

Introdução ao Azure ML e Mineração de Dados: Criando Um Exemplo De Regras De Associação No Azure Ml
Criando Um Exemplo De Regras De Associação No Azure Ml – O Azure Machine Learning (Azure ML) é uma plataforma de nuvem da Microsoft que oferece um ambiente completo para construir, treinar e implantar modelos de aprendizado de máquina. Suas funcionalidades principais incluem a criação de pipelines de ML, a gestão de experimentos, a automação de workflows e a integração com outras ferramentas da nuvem Azure. Na mineração de dados, o Azure ML permite a exploração e análise de grandes conjuntos de dados para descobrir padrões, insights e conhecimento valioso.
Neste contexto, exploraremos a aplicação de regras de associação, uma técnica de mineração de dados que identifica relações frequentes entre itens em um conjunto de dados transacional.
Regras de associação são um método usado para descobrir relações interessantes entre variáveis em grandes conjuntos de dados. Elas são frequentemente representadas na forma “Se X, então Y”, onde X e Y representam conjuntos de itens. Um exemplo em um cenário de negócio seria: “Se um cliente compra um produto A, ele também tem alta probabilidade de comprar o produto B”.
Essas regras podem ser usadas para melhorar recomendações de produtos, otimizar estratégias de marketing e aumentar as vendas.
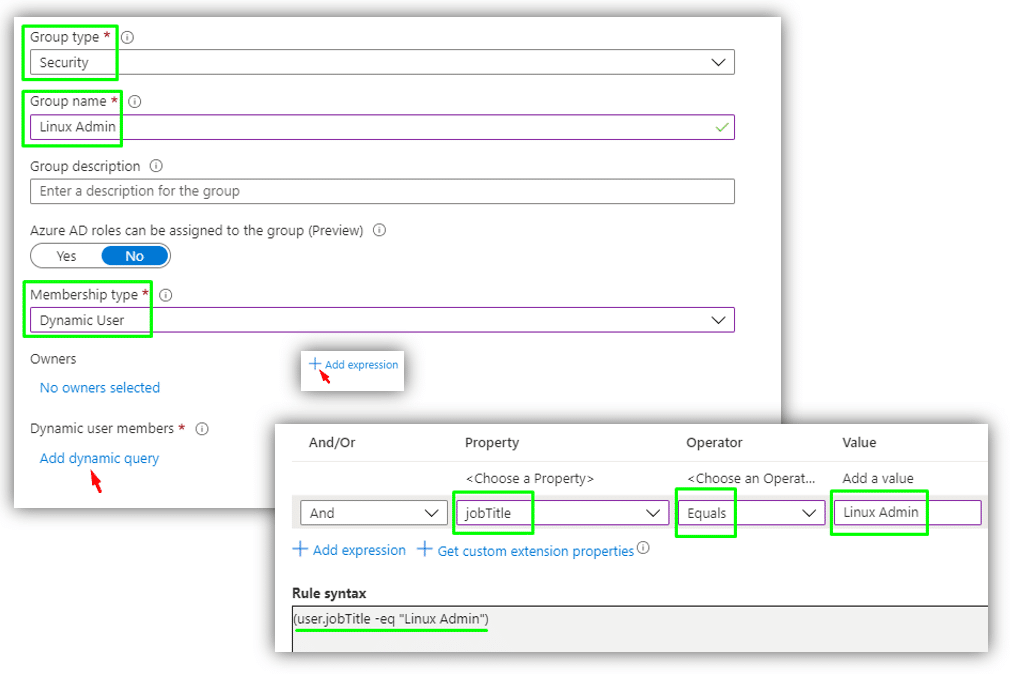
Para configurar um ambiente de trabalho no Azure ML para este projeto, você precisará criar um workspace, importar os dados e instalar as bibliotecas Python necessárias, como o `mlxtend` para a aplicação do algoritmo Apriori. A criação do workspace envolve a seleção de uma região e a configuração de recursos computacionais.
Preparação dos Dados para Análise
A preparação de dados é crucial para o sucesso de qualquer análise de regras de associação. Este processo envolve a importação do conjunto de dados, a limpeza e tratamento de valores ausentes ou inconsistentes e a organização dos dados em um formato adequado para o algoritmo Apriori. Um exemplo de conjunto de dados pode incluir informações sobre compras de clientes, com cada linha representando uma transação e cada coluna representando um item comprado.
| ID Transação | Item 1 | Item 2 | Item 3 |
|---|---|---|---|
| 1 | Leite | Pão | Ovos |
| 2 | Pão | Manteiga | |
| 3 | Leite | Ovos | Suco |
| 4 | Pão | Leite | Manteiga |
Valores ausentes podem ser tratados com a substituição pela média, mediana ou moda, dependendo da natureza dos dados. Valores inconsistentes, como nomes de itens escritos de maneiras diferentes, precisam ser padronizados. Os dados devem ser transformados em um formato apropriado, como uma lista de transações, onde cada transação é uma lista de itens.
Seleção e Aplicação do Algoritmo Apriori
O algoritmo Apriori é um algoritmo clássico para descobrir regras de associação em conjuntos de dados transacionais. Ele é baseado na geração de conjuntos frequentes de itens e na utilização desses conjuntos para gerar regras de associação. Embora eficiente para conjuntos de dados menores, ele pode ser computacionalmente caro para conjuntos de dados muito grandes. Existem outros algoritmos, como FP-Growth, que podem ser mais eficientes em alguns casos, especialmente para grandes datasets.
FP-Growth utiliza uma estrutura de dados chamada FP-tree para melhorar a eficiência do processo de mineração. A escolha entre Apriori e FP-Growth depende do tamanho e características do dataset.
A implementação do algoritmo Apriori no Azure ML pode ser feita usando Python e a biblioteca `mlxtend`. O código abaixo demonstra um exemplo de como aplicar o algoritmo Apriori:
# Importar bibliotecas necessárias
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
# ... (pré-processamento dos dados) ...
# Aplicar o algoritmo Apriori
frequent_itemsets = apriori(dataset, min_support=0.2, use_colnames=True)
# Gerar regras de associação
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.7)
# ... (interpretação dos resultados) ...
Os parâmetros principais do algoritmo Apriori são: support (suporte mínimo para um conjunto de itens ser considerado frequente), confidence (confiança mínima para uma regra ser considerada válida) e lift (levantamento, que mede a força da associação entre os itens, acima de 1 indica uma associação positiva). Ajustar esses parâmetros permite controlar o número e a qualidade das regras geradas.
Um suporte mais baixo gera mais regras, mas pode incluir regras menos relevantes. Uma confiança mais alta garante regras mais confiáveis, mas pode reduzir o número de regras encontradas.
Interpretação dos Resultados
Os resultados do algoritmo Apriori são tipicamente apresentados como uma tabela de regras de associação, contendo informações sobre os antecedentes (itens que implicam outros itens), consequentes (itens que são implicados), suporte, confiança e levantamento. Regras com alto suporte, confiança e levantamento são consideradas mais relevantes, indicando uma forte associação entre os itens.
| Antecedente | Consequente | Suporte | Confiança | Levantamento |
|---|---|---|---|---|
| Leite, Pão | Ovos | 0.4 | 0.8 | 1.5 |
| Pão | Manteiga | 0.3 | 0.75 | 1.2 |
| Leite | Ovos | 0.35 | 0.7 | 1.3 |
| Ovos | Suco | 0.25 | 0.625 | 1.1 |
| Pão, Leite | Manteiga | 0.2 | 0.5 | 1.8 |
As implicações de negócio das regras de associação descobertas podem ser significativas. Por exemplo, a regra “Se um cliente compra leite e pão, ele também compra ovos” sugere que esses itens poderiam ser agrupados em promoções ou colocados juntos nas prateleiras para aumentar as vendas.
Visualização dos Resultados
A visualização das regras de associação pode facilitar a compreensão e interpretação dos resultados. Métodos comuns incluem gráficos de rede e tabelas. Em um gráfico de rede, cada item é representado por um nó, e as regras são representadas por arestas conectando os nós. O peso da aresta pode representar a confiança ou o levantamento da regra.
Nós maiores podem representar itens com maior suporte.
Por exemplo, a regra “Se um cliente compra Leite e Pão (nó maior e mais escuro), então ele compra Ovos (nó menor e mais claro)” seria representada por uma aresta conectando os nós “Leite e Pão” e “Ovos”. A espessura da aresta seria proporcional à confiança da regra. A cor dos nós pode representar categorias de produtos, por exemplo, laticínios (azul), padaria (marrom), etc.
A representação visual permite uma rápida compreensão das relações entre os itens e a força dessas relações.
Considerações Finais e Melhorias, Criando Um Exemplo De Regras De Associação No Azure Ml
O algoritmo Apriori tem algumas limitações, como a sua complexidade computacional para grandes conjuntos de dados. Alternativas, como o FP-Growth, oferecem melhor desempenho nestes casos. A qualidade dos dados também afeta a qualidade das regras geradas. Dados incompletos ou inconsistentes podem levar a regras imprecisas ou enganosas. A interpretação dos resultados requer cuidado, considerando o contexto de negócio e a validade das regras geradas.
Melhorias no processo de análise podem incluir a utilização de técnicas de pré-processamento de dados mais sofisticadas, a exploração de outros algoritmos de regras de associação e a utilização de métricas de avaliação de desempenho, como precisão, recall e F1-score, para avaliar a qualidade do modelo.
Quais são as principais limitações do algoritmo Apriori?
O Apriori pode ser computacionalmente caro para grandes conjuntos de dados e apresenta dificuldades com itens raros.
Existem alternativas ao algoritmo Apriori?
Sim, algoritmos como FP-Growth e Eclat são alternativas mais eficientes para conjuntos de dados extensos.
Como posso avaliar a qualidade das regras de associação geradas?
Métricas como suporte, confiança e lift são cruciais para avaliar a qualidade e relevância das regras. A interpretação contextual também é fundamental.